
Let’s analyze one of the typical tasks of organizing CI / CD processes, namely, tracking and maintaining the structure of objects for the Snowflake cloud database. From ready-made solutions, first of all, we paid attention to the provider for Terraform, which is called chanzuckerberg/terraform-provider-snowflake.
After taking a closer look at the functionality available and how it is implemented, we came to the conclusion that its scope is very specific and I would not recommend using it, at least for CI / CD processes for storage objects, or at least in the current implementation of the provider. Perhaps in the future this provider will be finalized, but its current implementation raised a lot of questions for me.
Once again, I would like to note that we are considering CI / CD tools for maintaining the data model, first of all. Database administration, in our consideration, is relegated to a secondary plan. If we are solving a problem related to maintaining access rights differentiation systems, or maintaining the integrity of objects responsible for changing metadata, then perhaps this toolkit can be used.
Let’s go through the main points that arise when using this Terraform provider for Snowflake.
The first thing we may encounter is that Snowflake allows you to create objects in both uppercase and lowercase, but when manipulating objects through the Snowflake connectors, or through the JDBC driver, Snowflake automatically converts the names of objects to uppercase and only names, enclosed in quotes is processed in the case in which they are passed, and Terraform creates objects in the passed case, regardless of the use of quotes.
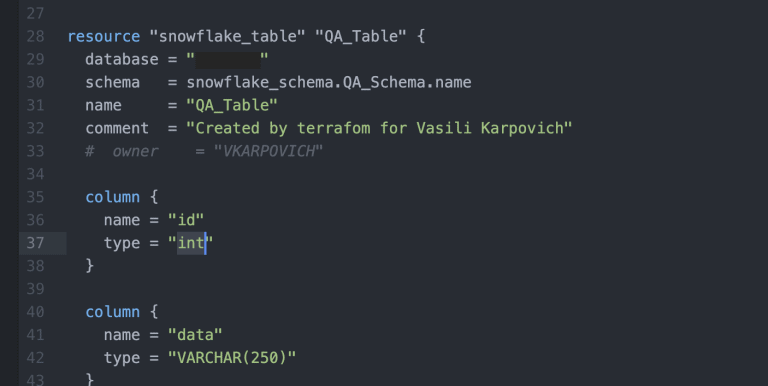
As one of the possible workarounds, we can introduce an internal rule for naming objects only in uppercase. If we specify a data type with a lower case character, the implicit conversion inside Snowflake will change this to the final internal data type and the Terraform script will of course not be aware of this.
Every time Terraform tries to check for changes in our environment, it will always see that there are differences, but nothing has really changed. This most likely happens because Terraform applies the script and after that takes the current state of the received object, which was obtained inside Snowflake and it may differ from the original Terraform script. For example, our column had an integer data type. In fact, when Terraform applied the changes, it gets the description that this object was created as number.
It turns out that we recorded the change in Terraform, deployed them through Terraform to Snowflake, but the state of the objects inside Snowflake Terraform got completely different than we specified in the script, and now Terraform will consider every time that the object should be modified.

The most common problems:
| Available input data type | Will be always converted in Snowflake |
| INT | NUMBER(38,0) |
| TEXT | VARCHAR(16777216) |
| VARCHAR(ANY SIZE) | VARCHAR(16777216) |
The most common, albeit syntactically permitted, constructs that lead to this result are attempts to create fields with type integer. The implicit type conversion in Snowflake will create a column with type number 38.
The text data type will also be converted to varchar with a maximum length, and if we create a varchar with some kind of restriction, for example varchar(10) inside Snowflake, we will still get the maximum size of the data type. It remains only to state that at the moment, the provider does not know how to work with these analogues of data type names.
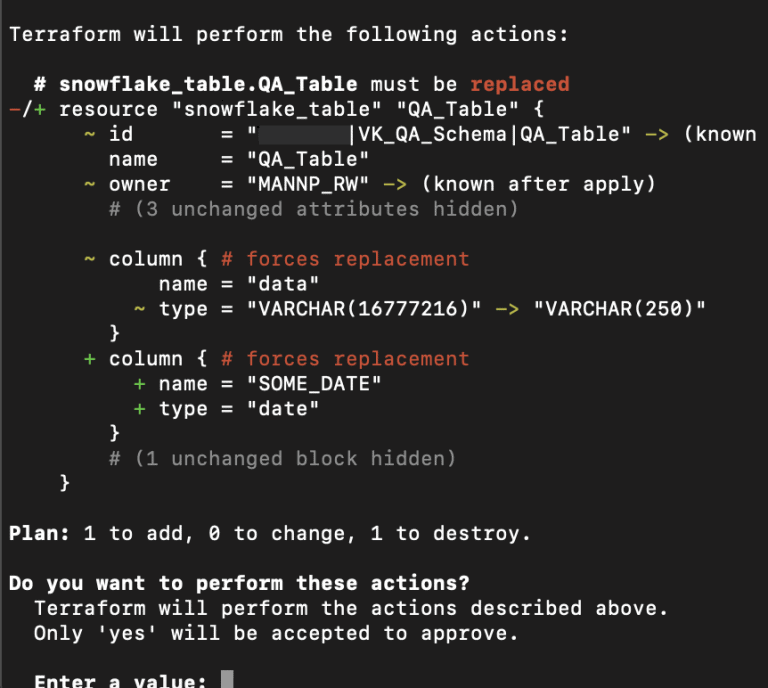
The next type of problem. Every time we try to change the data types in a table column, Terraform, having the latest data snapshot from Snowflake, tries to change the data type inside the column in the table on the fly, but trying to add a new column to the end of the table causes Terraform to decide to recreate this table by simply destroying and creating a new object. This seems to be due to the fact that the Terraform provider was written as a resource maintenance tool, such as resource maintenance in a cloud environment where simply re-creating a new resource should not be a problem.
There are certain mechanisms (and in other Terraform providers too) for seamless integration, such as blue-green deployment, but in the provider that is used with Snowflake, there are no mechanisms for implementing such integration. To add a new column at the end of the table one could set a default value.
However, the provider does not provide such an opportunity. For this column, we cannot process or write some script to change our object in the database. Even if we wanted to not only delete the object with the loss of all data, but precisely transform this object in a controlled manner, or create a copy of this object nearby , copy the source data to new objects, delete and then rename the copy of the object to the target name – the current version of the provider does not provide such mechanisms.
This point is one of the most significant, using Terraform to maintain data storage objects becomes very dangerous when unnoticed changes inside the schema and inside the table structure can lead to the loss of all data accumulated in this object.
There are objects in Snowflake that do not store data. When working with them, destruction and re-creation are not so scary. For example, views, or access control objects, they do not contain history and do not contain data. In fact, metadata is the only thing that is needed for these objects, and if we recreate some kind of role, then such a mechanism will probably work. However, the implicit conversion on the Snowflake side can lead to unexpected results here as well.
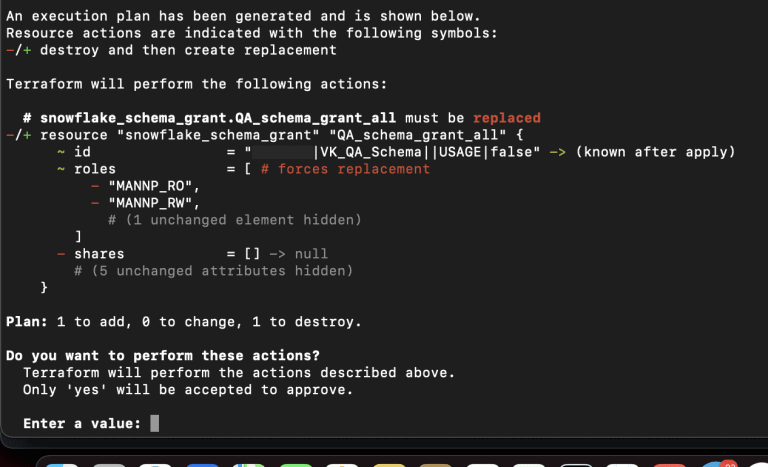
In our example, we have certain roles that are embedded in the access rights distribution system. We have created a read-only global role and a read/write global role. We are trying to create a schema and transfer privileges for the public group. Snowflake interpreted public as the entire set of subroles included in public, most likely public – a keyword with internal logic embedded inside snowflake.
Terraform, applying a certain script, accepts these changes and makes them into its structure, but back from Snowflake Terraform receives a list of roles that are inside public. We again get a situation where the script seems to be syntactically correct, successfully applied to the environment, but the provider will assume every time we run that we have made changes to the environment.
For now, I would recommend not using the chanzuckerberg/terraform-provider-snowflake provider for Terraform. As alternative solutions for Snowflake, you can consider more mature solutions such as:
- Flyway
- Snowchange (Snowflake-Labs/schemachange)